We present MicroCinema, a straightforward yet effective framework for high-quality and coherent
text-to-video generation. Unlike existing approaches that align text prompts with video directly,
MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage
process: text-to-image generation and image&text-to-video generation. This strategy offers two significant
advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as
Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b)
Leveraging the generated image, the model can allocate less focus to fine-grained appearance details,
prioritizing the efficient learning of motion dynamics.
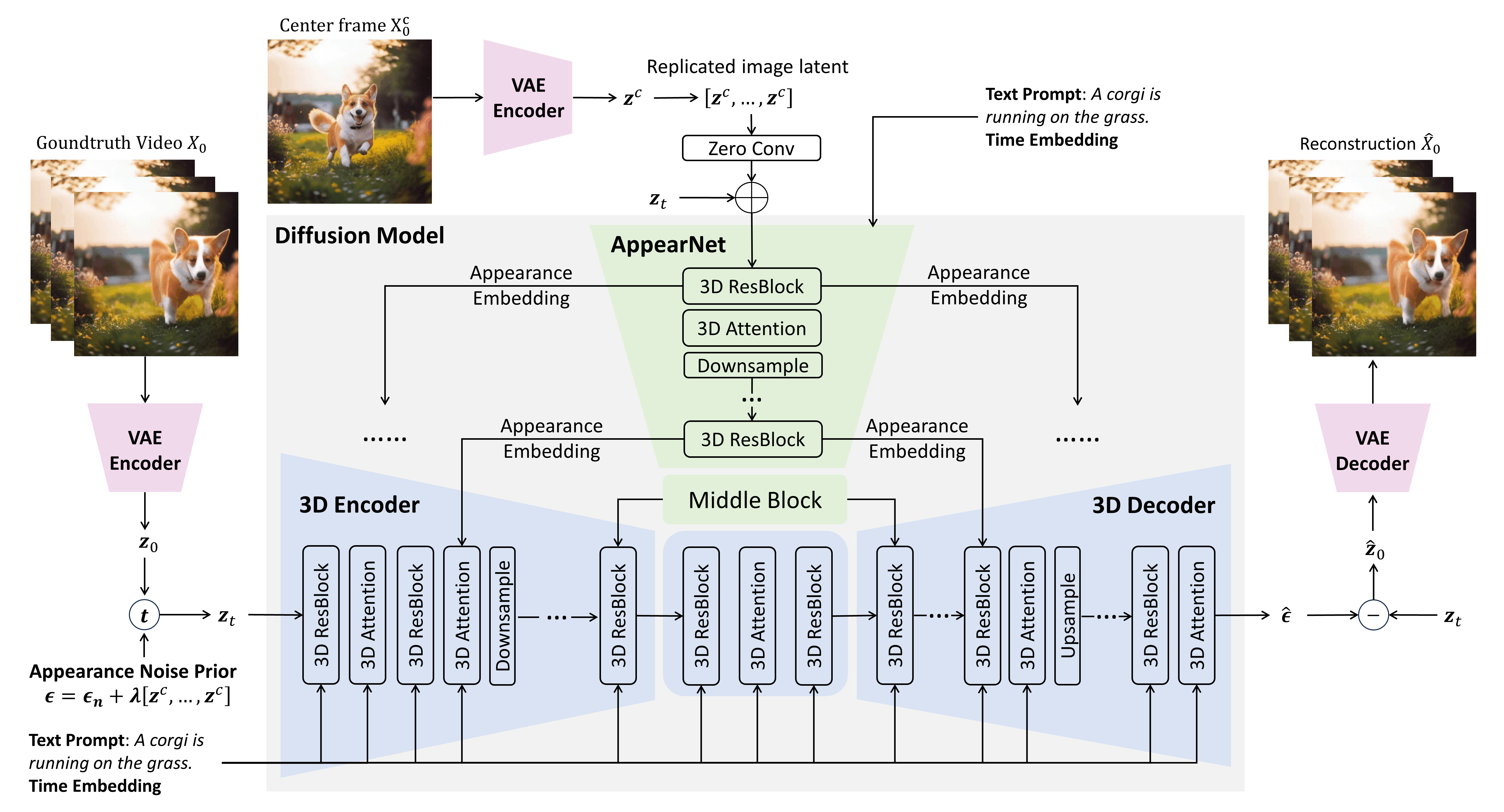
To implement this strategy effectively, we introduce two core designs. First, we propose the
Appearance Injection Network, enhancing the preservation of the appearance of the given
image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at
maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema
to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive
experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves
SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on
MSR-VTT.